2 July 2020
Lifting the Veil on AI

John Cardoso
One of my favourite TV shows is West World. For those unfamiliar, West World in many ways is the ultimate experiment in machine learning and artificial intelligence (AI). The show is set in a world that has been created by humans but is inhabited by “hosts” – life-like robotic replicas of humans. At first, the hosts appear to only exist to help humans live out their deepest, darkest dreams and fantasies. However, *spoiler alert* as the series unfolds, it is revealed that the hosts are designed and programmed to learn human behaviour, and ultimately learn consciousness to achieve fidelity. The theory being this would then allow the human conscience to be backed up, automated and replicated at scale, enabling immortality and the creation of a superior race.
*Spoiler alert*, of course, the plan backfires, because the hosts only get exposed to the very worst of humankind. They learn to be evil, violent and dangerous and spur an uprising to take out the human race entirely. But that’s TV, back to real life.
For many people, when they hear the words machine learning or AI, they recoil. It could be for several reasons, ranging from the perception that it’s all too complex and magical to wrap their head around, to the belief that it involves training robots and computers to take our jobs before eventually killing us all! Or simply because people have been watching too much West World.
In reality, machine learning is pretty simple. It’s not magic, it’s pure mathematics – and none of the equations are new, we’re just learning to use them differently. There’s no silver bullet, like any new problem it requires a lot of trial and error before you find the right solution.
How do you solve a problem like false positives?
At Intelematics, we have used machine learning to train a robot (that we’ve named ‘Toasti’) to interpret journalistic traffic incident data from various inputs and communicate it to our customers, many of who provide GPS information to drivers Australia wide. When we talk about journalistic data, we’re referring to anecdotal information written by humans, for humans, that we receive from sources (e.g. emergency services, road authorities) through either social media or email or in API or FTP format.
There are a few reasons we wanted to automate this process – the first being driver safety. By programming a machine to understand human language and context, all the thinking is done for the driver. In essence, we are translating human messages into machine language. This means that inbuilt GPS’ will take the information they are receiving and reroute the driver if deemed necessary. When a driver doesn’t have to interpret any of the information themselves, it simplifies the decision-making process of driving – and the simpler the decision-making process for the driver, the safer.
We also wanted to be able to deploy accurate messages more quickly to ease driver frustration and improve the efficiency of the road network. A message informing an incident that has caused lane closures and therefore delays along a particular route is no good to a driver if they are already travelling along that route. A message needs to reach a GPS in time for it to be able to redirect drivers along the fastest possible route.
Intelematics is by no means the first company to automate the process of interpreting traffic data, to communicate navigation information to drivers. Many companies have successfully used it to achieve some level of velocity and scale. However, we did pave the way to automate journalistic data and to achieve velocity and scale, with great accuracy. We experience very few false positives, which refer to test results that wrongly indicate a particular condition. Too many false positives can wreak havoc with the road network – let me give you an example.
Berlin-based artist, Simon Weckert, set out to create the world’s first virtual traffic jam. The idea first came to Mr Weckert when he attended a public demonstration and saw that Google Maps was mistaking the people gathered at the location for cars on the street because it was solely relying on location data from people’s phones. So, he decided to create a scrum of digital devices to see how Google Maps would react.
He filled a little red wagon with dozens of devices and walked the streets of Berlin. He left a trail of digital destruction in his wake, as each street he walked down with his wagon in tow turned from green (Google Maps sign for smooth sailing) to red (indicating a congested area that should be avoided). It’s fascinating stuff – check out the video below to see how it all worked.
What this shows is how easy it is for mapping services to register false positives when the right checks and balances aren’t in place. Take, for example, vehicle probes that determine the presence of vehicles on the road. If there was no traffic on the road for a certain period, a conventional AI solution might conclude that the road is closed, and provide that information to drivers, causing them to avoid the area and look for alternative routes, causing unwanted disruption. This solution takes a ‘one size fits all’ approach, and while this would work in countries with high-density populations, in Australia, it’s not as accurate – due to our sparse population. It is a given – authorities must have access to accurate information around road accessibility, particularly in times of emergency that require swift evacuation.
The approach we take at Intelematics is different. Every piece of information we receive is verified through three sources. If we get information through probes (e.g. from GPS units) saying a road is congested, we then verify it against sensors located in copper cabling under the roads. While many companies have access to probes, not many have access to these in-road sensors. If the sensors also tell us that the road is congested, we then verify it against the journalistic data we receive, which could be a Tweet from a road authority, warning of an incident on a particular road. Only once the information has been through the three source verification process, do we communicate an alert. We take the perspective of the driver, the road, and reputable third parties to give context. We don’t make assumptions, and as a result, we record only a few false positives.
While this gives us incredibly accurate information, it is also a time-consuming process – so you can understand why we were so keen for it to be automated.
How to train your robot
When it came to automating the process, we knew it would be necessary to invest in training data sets upfront. Training data sets are the difference between your machine learning and AI model working and not working. Let me give you another example.
Devices like Amazon Alexa and Google Home are supposed to be programmed to register your voice, interpret what you’re asking and then carry out the command. They are supposed to use machine learning and AI to perform this function. We all get frustrated with these devices because they so often fail to carry out seemingly simple commands; however, I would argue they’ve been set up to fail.
These devices haven’t been programmed with proper training sets. In essence, that means the machine learning hasn’t even occurred. Every time a Google Home, or an Amazon Alexa fails to perform a task, the information is sent to an offshore centre, where a human listens to your voice and interprets your command, and then codes that information back to a database that will be used to train the machine better. This means that these devices are on the equivalent of their AI and machine learning ‘learners’ plate’ – they haven’t done their 120 hours, and they’re not yet fully competent. They’re apprentices, learning on the job.
On the other hand, our Toasti has already put in the work to become a qualified expert before being released to the market. The way we did this was straightforward. As I said, there’s no magic in machine learning – it’s all about repetition.
We introduced Toasti to six other human colleagues who would teach it how to interpret data. Whenever a piece of communication from social media, an email, an API or FTP came in, we would assign the key information a code, to then upload to our interface to be communicated to our customers. For training purposes, the key information we focused on was the location, cause and effect.
For example, if we received a piece of communication that said: single-car incident at Somerton Road, emergency services on-site directing traffic, expect delays – then our team of people would input to our interface (for example) code 201 for the location (Hume Highway, Somerton exit specifically) 301 for the cause (a single-car incident) and 401 for effect (lane closures causing delays). Of course, our probes and sensors would’ve already detected unusual activity in the area, but we code the information into the interface only after it has been validated through a third-party source.
That coded information would then be translated into machine language and fed into GPS’ provided to drivers by our customers, which then helps navigate routes accordingly.
While initially, this process was carried out by humans, Toasti was learning from its human colleagues and trying its hand at coding the right information into the interface at the same time. In the early days, each of Toasti’s output was verified by a human operator before being uploaded to the interface. This was Toasti’s learning period. Only once Toasti reached 85% accuracy was it allowed to then upload coded information to the interface unsupervised.
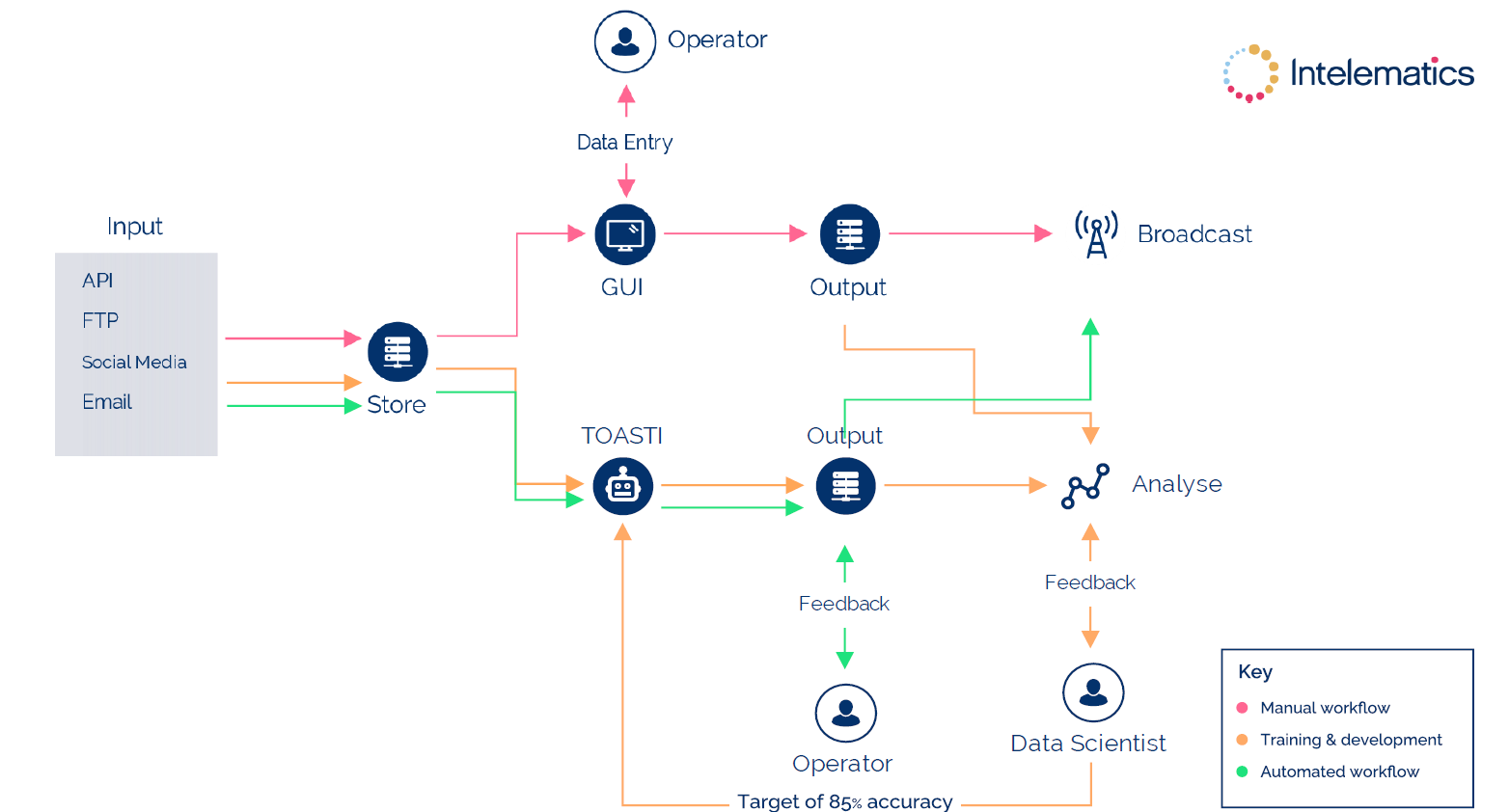
The challenge for Toasti was that unlike machines, there’s no standardised approach to human communication. People can say the same thing in umpteen different ways, and we had to train Toasti to recognise that. One way we did this was by replicating the training process state by state. The reason is that each state has its quirks in the way it communicates traffic incident messages.
For example, we found that people who worked at a road authority in New South Wales may have a vastly different way of communicating messages than people working at a road authority in Victoria. This is most likely because they’ve been trained by different people and have different organisational protocols and ways of doing things. We also found that people state by state would make similar spelling mistakes on particular roads, so by isolating these, it became easier to teach Toasti to register the incorrect spelling variations and still communicate the right information. Toasti trained on each state for three months before reaching the 85% accuracy threshold – it’s a monotonous and time-consuming process, but it’s what’s required to achieve the desired results.
Toasti is off its L-plates, passed its probationary period and has now graduated to a fully licensed operator. Since Toasti has taken over the role of our human team, we have seen every verified message communicated to drivers within three minutes of receiving it. Before Toasti, messages could’ve taken 10-15 minutes, or longer during a busy patch – the point being that it was dependent on how quickly a human could operate. By having the information more quickly, drivers can be confident that they have the most up to date route information, which results in a safer and more efficient road network. – and there is no decline in performance during peak hours.
As for our human team – now that Toasti is fully competent, they’ve been able to move away from data entry and into product design and co-creation. They’re also adding more value to our business than ever before through business and technical support, including knowledge management and ensuring reliability.
What we’ve done with Toasti isn’t necessarily achievable for some of the bigger traffic data and information companies that operate globally. There would be too much of a time investment to scale this globally. However, for customers who need granular, specific and accurate information on Australian roads, they can be confident that Intelematics and Toasti have them covered.